Software Engineering
SOLID principles, excuse me? What exactly are we talking about?
30 November 2022 | Por Juan I. Echaide
How to get a concrete benefit from these principles

You’ve heard phrases like our title related to SOLID principles and/or you said it yourself during a job interview, a daily meeting, maybe on school or at a course. Perhaps you know about this subject in theory but you’re not entirely sure about how to use it. Don’t worry that’s common.
Almost everybody involved in software development has heard about them at least once but not everybody is fully able to explain in his/her own words the immediate utility of their usage. Happens to be very clear in theory but not that clear in practice applied to a real specific solution. We must add that in the thrill of a project it’s almost unavoidable to think for a second: “Why complicate things that way, right?”
We want you to start considering these principles as real “life savers” and “simplifiers” during the roadmap you are regularly walking through as a developer. Ready for a change? Will you let SOLID principles help you?
Case study. Small example with Typescript
We decided to give our overview with TypeScript but remember that you can apply SOLID to any other language. We decided to go for this example because of its advantages by the time of needing to give some architecture definitions to apps developed with Angular, React, Node JS, and similar technologies.
Commonly the boilerplate that comes with the mega libraries or framework takes us a little bit far from architecture principles but decoupling layers enough to work with SOLID in our business logic despite the unavoidable boiler plate we need to make things work allows us (among many others) to migrate between technologies without necessarily starting all over again.
A kick-starter
SOLID are principles of architecture. Which means that we are talking about criterions not dogmas. All these principles interact with each other and of course every concrete software solution differ from other even applying them correctly.
The interaction means that is not that strange to find ourselves dealing with the contradiction of a principle because of following another one. Is no other thing than logic at work. Many times, we will need to trade or negotiate between the strict appliance of two SOLID principles. The correct answer will always depend on what our app needs and which of the possible decisions takes us closer the clean code we are after to.
This leads us to the first conclusion that these principles should be considered a help and should be used with logic not as a sort of cult and in every technology it will be slight differences on how to implement them.
And… here they are:

The “S”: Single responsibility. Less is more
The mantra behind this principle says that we should keep things simple following the concept of “one class or component = one responsibility (or reason to change)”. We work with apps that must be modularized enough to securely escalate reusing our code. This principle sets a criterion to design those modules we work with. Please bear in mind that this concept applies to functional paradigm as well as it works for oriented object paradigm.
Our components, functions, or classes, modules at the end, should have one and only specific responsibility and not become in a “one men orchestra” kind of implementation with a lot of different stuff inside. During the lifecycle of an app changes will come every day and the impact that a new requirement or design change that could come up in our code should be minimum. We don’t want to propagate the rework from one specific functionality to everywhere else in our app. Ideally one class or component should have only one job to do.
Also, bugs, gaps, errors and wrongful or unpredictable behaviour in general will be often “encapsulated” there inside our module allowing us fixing them with less effort. We will recap this idea when we meet the “L” of SOLID, but for this principle is enough to comprehend that our module has to be responsible for a single functionality and it has to “change”, during the runtime behaviour, or even in a further refactoring, for only one single reason.
We’re going to use the business model of a parking lot, just to have a little business logic that might allow this to follow all the principles’ appliance in one single project instead of isolated examples of each principal by its own. We could reduce this business logic in one single user story: “as a user I want to be able to park pay and take out my after a staying”.
Let’s see an example of a Vehicle which has addNewVehicle method that should interact with our database making a scripture and in our business logic we want to be modified adding new ones, at least. Applying SR leads us from something like these:
// Without SR
class Vehicle {
constructor(private owner: string, private plaque: string) { }
get owner(): string {
return this._owner;
}
get plaque(): string {
return this._plaque;
}
addNewVehicle(): void {
// save vehicle in our DB.
}
}
To something like the code below where we could see “splitted” or “modularized” classes separating or segregating responsibilities or functionalities:
// with SR
/*entity with single responsibility */
class Vehicle {
constructor(private _owner: string, private _plaque: string) {}
get owner(): string {
return this._owner;
}
get plaque(): string {
return this._plaque;
}
}
interface Storage {
add(vehicle: Vehicle): void
}
Why is this change good for us? Let’s suppose that during our roadmap some business requirements regarding the way in which we must manage the parking lot (e.g.: Updating stored data of a single vehicle).
In our first ‘non-segregated’ scenario, we must put our hands in the Vehicle class with possibilities of unexpected errors not only related to the favourite foods array but also on code we don’t want to change at all. Vehicle class should change only if something strictly related to the vehicle entity in our business logic changes (e.g.: new property adds like model of vehicle). Vehicle still has plaque and owner properties, no changes on that, so it shouldn’t change because a modification coming up on how that array pushes o pops values.
In our second or properly segregated scenario we might update our food preferences class keeping intact our vehicle class, like this:
// with SR
/* entity with single responsibility */
class Vehicle {
constructor(private owner: string, private plaque: string) { }
get owner(): string {
return this._owner;
}
get plaque(): string {
return this._plaque;
}
}
interface Storage {
add (vehicle: Vehicle): void
update(vehicle: Vehicle): void
}
This principle could be challenging when it comes to deciding if segregating or not a method inside a class that is not that clear if it has a different reason to change if we analyse it in terms of code. We’re going to improve this example using real design patterns that you can find in production apps today.
The “O”: Open-close. The iron man armour
Let’s talk a little about behaviour. The Vehicle class is seeming to be a static definition. As we said this is good, but we also know that our person needs to behave to make our business logic work. Otherwise, the definition of the entity wouldn’t be useful. In the example given above we segregated functionalities into two different classes which is a start. But what if we need to apply the same behaviour to different classes we might find ourselves repeating code.
Repeating code is not the only undesirable thing that might happen. Again, the coming changes are the iceberg we want to escape from with a dribble. Same entities could behave or could be managed by some other functionalities in many ways which immediately tells us that some things will change but some other not, so split them could be the best idea.
The segregation allows to keep intact the modules we use in our logic, which means “close to changes”. Off course that closure it’s not sculpted on stone is about thinking the design of each class, component, function, etc., to be ideally “done forever” as a continuous exercise. But the trick here is not only about the closure to changes but also the opening to extension.
We must smart code our modules in the way they could be extended, which means in most cases do not specify them too much. We should design them like bricks of a building game, connectable but no breakable. One concrete benefit from SOLID is forging ourselves the habit of an iterative or recursive (re)thinking of our code with principles as a sort of filter. This habit enhances our skill to develop faster and better in general.
Another remarkable fact is that the reusable code for the extensions of behaviour we should use for our classes or components following this principle provides us another benefit. Allows us to send some part of our solutions for a class or component to a higher level of our code, becoming general solutions available for others. This process is the so called “abstraction” and allows us to slice, segregate, separate, or abstract (properly speaking) as many layers as useful.
The interfaces in the case of TS as well as in Java, .NET and many OOP based or at least strongly typed languages allows us to dress our classes with iron man armour thru abstraction. We can give behaviour to our classes all the way through our app writing once and implementing ’n’ times.
As an abstraction they are there is no logic at interfaces in TS, but a prototype, a signature, in the way of a property — data type pair. Enough to implement and declare all those specific aspects that concrete implementation requires in our class preserving consistency in our business logic at the same time of keeping our code DRY. This is the so called “override”.
In the case of TS this possibility of abstraction goes even further from interfaces. Because the Generics allows to abstract the data types allowing us to manage in multiple layers our logic and our entities definition. The code below is a small example of this abstraction without functions and only for explanation purposes:
We will give a more realistic example below but for now keep in mind that the type “Vehicle” is being extended because we can handle the park-in/park-out beyond as well as we want to diversify our possibilities of Vehicle as splitted entities.
First, we store in constants the prices that we’re going to earn for each kind of vehicle:
/* price constants */
enum Price {
Car = 100,
Motorcycle 50,
Van = 150
}
We can extend our Vehicle class but this time using inheritance. As every suggestion we could make in terms of abstraction and inheritance the utility will depend on its conveniency for the business logic that we’re working on:
/* extension of vehicle for Car */
class Car extends Vehicle {
price: Price.Car;
}
/* extension of vehicle for Car */
class Motorcycle extends Vehicle {
price: Price.Motorcycle;
}
/* extension of vehicle for Car */
class Van extends Vehicle {
price: Price.Van;
}
We can extend your Vehicle class but this time using inheritance, assuming that there is profit for our business logic in the segregation of entities for the different kind of vehicles:
/* extension of vehicle for Car */
class Car extends Vehicle {
price: Price.Car;
}
/* extension of vehicle for Car */
class Motorcycle extends Vehicle {
price: Price.Motorcycle;
}
/* extension of vehicle for Car */
class Van extends Vehicle {
price: Price.Van;
}
And now the abstraction using interface of the parking behaviour that we want to implement later in every concrete type of vehicle:
interface Parking<T> {
driveIn: (vehicleId: string) => {};
driveOut: (vehicleId: string) => {};
}
Finally, the promised implementation:
class ParkCar implements Parking<car> {
driveIn: (vehicleId: string)=>{
/* concrete override logic for parking in car */
};
driveOut: (vehicleId: string) => {
/* concrete override logic for parking out car */
};
}
class ParkMotorcyle implements Parking<Motorcycle> {
driveIn: (vehicleId: string) => {
/* concrete logic for parking in motorcycle */
};
driveOut: (vehicleId: string) => {
/* concrete logic for parking out motorcycle */
};
}
class ParkVan implements Parking<Van> {
driveIn: (vehicleId: string) => {
/* concrete logic for parking in van */
};
driveOut: (vehicleId: string) => {
/* concrete logic for parking out van */
};
}
Please, keep in mind that we can use interfaces for this good practice but the concept of “open to extension” in the way of this principle goes beyond the reserve word explicitly recognized by a language or framework as “interface”. You will see many features that allow us to extend behaviour without changing our modules that are not exactly interfaces.
That’s the case of High Order Components and/or High Order Functions on JS and TS. This components or functions, as its names say, are higher modules of code that receives another module as a parameter wrapping it as another kind of “iron man armour” that permits behaviour extension. We might say they are a sort of “empty suit” where you can include logic or data persistence to enhance the robust module.
There are also mega libraries as React that take this idea of HOC or wrappers a little bit further. Using features like state Providers from third party libraries as Redux or the native Context API we are extending behaviour by this same principle. Even when the syntax and boilerplate might not sound similar at the beginning, we are following SOLID.
Same things happen with the famous “hooks” specially the custom ones we can design. They permit us accessing behaviour and data from several spots of our app decoupling or splitting code and keeping the open-close principle.
An arch snack
Before seeing some code and giving a more realistic example of open-close that will clarify the principle is better to make a technical stop in our trip and talk about architecture. Just as a little snack of architecture.
We said that responsibilities should be unique for each module of code we design. But keep in mind that SOLID principles work as fractal or the physics of a crystal. We can go from top to bottom of the code blocks that composes our app, but we must find out at any level a replication of this principles.
It doesn’t matter if we are encapsulating or gathering ’n’ quantities of them inside this ‘fractal’ coherency is what will robust our app in the end. Think your app as SOLID box containing infinite amounts of smaller SOLID boxes inside.
That’s the reason why the general responsibilities involved in the app should be segregated or separated properly. A good segregation into layers in its simplest version should have at least three layers to segregate the main three aspects that an app should consider: services, data, and UI. Layers over layers as an onion, working together but clearly differentiated. Once again every architecture principle as well as SOLID are not dogmas but an excellent guidance.
A simple way to measure how good are we working on segregating layers takes place when changes comes as we insisted before many times. Our ideal is that any trivial change should be “transparent” or “agnostic” from one layer to another. In simple words: show should go on without any turbulence for the layers we are not modifying.
E.g.: if we are noticed that the URI of an endpoint changed that change shouldn’t have any impact on data layer and UI layer. Another example: if the design of a view is changed to improve User experience shouldn’t impact in our service layer and should be none or minimum in our data layer.
There are several techniques to address an architecture with segregation and consistency as Model View Controller pattern, Model View Presenter pattern, Hexagonal Architecture and Clean Architecture which are appliable to both ends. Because of an extension limit we invite you to read anywhere else about these but encouraging to use them because of its enormous benefits.
In practice, the extension of behaviour for a class placed in one single layer often will take place to interact with another. If we provide our module with behaviour following open-close principle inside an architecture that behaviour will be somehow related to a process that happens in the “next” layer to be called in the execution. That’s why we needed this “snack” to give a small but correct example of open-close appliance.
Let’s suppose that we decided to go for MVC like Angular and other technologies do to keep it simple. We will have as many controllers as views our app has. In this case responsibilities are for Model to define “which” or “what” data should be shown, for View to define “how” that data should be shown, and for Controller to refresh view and data responding or reacting to users’ entries. Like this:
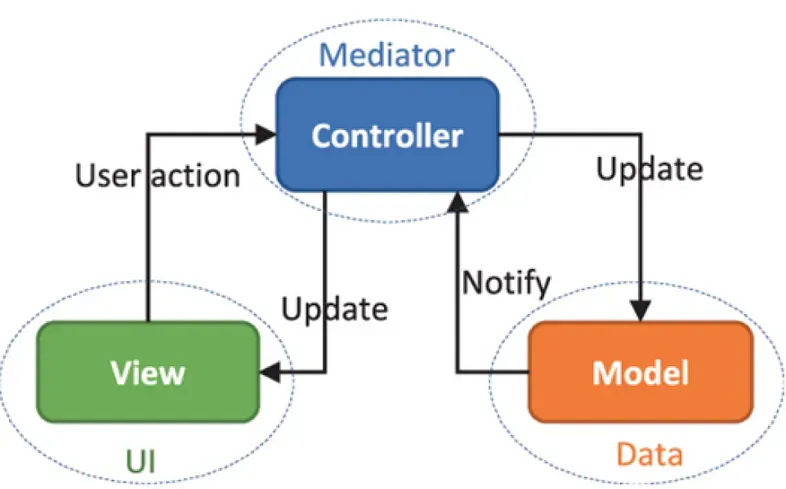
Back to road
For our overview we will see a slice of a MVC pattern using Repository pattern. This means that the data retrieved when the user interacts with our UI and the controller’s actions are triggered will not be obtained every single time from our Database.
Directly consuming data all the time from DB would have an enormous cost and a performance decrease. Imagine somebody asks you how many objects you have in a box in some shelf. You go there you open it and make a count, give an answer, and then you put the box in the shelf again. Let’s suppose that somebody else asks you the same later. Will you go again and open the box, make the count, and tell the answer again?
You already have your “data” in your temporary memory, you made the count recently, is more efficient for your own brain to get it from there than repeating the entire operation. That’s why we use repositories. To have an “in memory collection” of the entities, the data in the end, we want to retrieve in our app. We considerably reduce the number of operations in our DB.
We’re going to assume we have a Vehicles repo and controller that has the responsibility to call it in some scenario. E.g.: by the time of adding some new food preference (our model) to a person in our DB.
Let’s begin with the abstraction for the repositories using interface:
/* repository abstracted layer */
interface RepositoryInterface<T> {
add(entity: T): void;
update(ticketId: string, entity: T): void;
}
Then we must implement our Vehicle Repository:
/* repository concrete implementation for vehicles */
class VehicleRepository<T extends Vehicle> implements RepositoryInterface<T> {
add(vehicle: Vehicle): void {
// Save book in the database
}
}
We could use an abstract class that cannot be instantiated or use a concrete instance like this:
const vehicleRepository = new VehicleRepository<Vehicle>()
As we explained in our architecture snack responsibility of calling the repository will rely on our ticket controller in response to a UI event:
class VehicleController {
/* the rest of logic for the proper implementation of controller*/
addNewVehicle = (vehicle: Vehicle) => {
vehicleRepository.add(vehicle)
}
}
Just to give a good wrap-up of all these concepts our controller will respond to a UI event (which happens at the View) from our user in this case the action of adding a new vehicle that we are going to receive as a client in our parking lot.
The “L”: Liskov substitution. The mamoushka effect
This principle conducts as to think our code not only as small reusable pieces but replaceable ones. A module we code today might be wonderful for this state of roadmap, but changes always come to the party. Anytime we code a module we must develop it splitable but also easily replaceable by several smaller ones.
Sometimes posterior changes imply replacing a perfectly working code and is a good practice making the life of the future version of ourselves a little easier by then. If we design our module with this Liskov or substitution principle in mind we can make a fast refactor just putting most functionalities outside the module or inside new ones and making the changes we need in the specific spots.
You can picture it as matryoshka or mamoushka, boxes inside smaller boxes, not exposed at the beginning, but with a structure prepared to disassemble and separate without malfunctioning. This principle it’s not just coherent with single responsibility it looks like a consequence and complement of it. Because if we want to keep responsibilities unique without repetition we must design our code to be able to substitution anytime that we reach and overlap of responsibilities.
So far in our example, our repositories have responsibility of making simple CRUD operations, so our repository interface is good enough. But let’s assume that posterior change makes the crud operations get more complex. Also, we are going to switch the class and interface feature usage as we been implementing it a little bit to show the scope of possibilities you have.
We are coming from our interface:
/* repository abstracted layer */
interface RepositoryInterface<T> {
add(entity: T): void;
update(ticketId: string, entity: T): void;
}
And our concrete implementation for Ticket, like this:
/* repository concrete implementation for ticket */
class TicketRepository<T extends Ticket> implements RepositoryInterface<T> {
add(ticket: Ticket): void {
// Save Ticket in the database
}
update(ticketId: string, ticket: Ticket): void {
// update Ticket in the database with new data;
;
}
}
As we said before we’re not going to make a replacement because of a wrongful feature, this need comes up after a posterior change (e.g.: business is getting more complex). This means that we cannot escalate just like that the code we have without making things hard for ourselves to increase unit testing coverage as well as keep behaviour under control.
The change we’re going to introduce makes our code diverge (segregating interfaces in the way that we explain in the next principle) but then converging again in our concrete repository class. So, we’re going to split the CRUD operations into two different kinds: write and read.
interface IWrite<T> {
create(item: T): Promise<boolean>;
update(id: string, item: T): Promise<boolean>;
delete(id: string): Promise<boolean>;
}
interface IRead<T> {
find(item: T): Promise<T[]>;
findOne(id: string): Promise<T>;
findBetweenDates(start:string, end: string): Promise<T>;
}
Then, we can implement the concrete Ticket Repository:
/* repository concrete implementation for ticket */
class TicketsRepository<Ticket> implements IRead<Ticket>, IWrite<Ticket> {
find(item: Ticket): Promise<Ticket[]> {
/* for explanation purposes we instatiate a Promise
your query shoulde be here */
return new Promise(() => [])
}
findOne(id: string): Promise<Ticket> {
return new Promise(() => {})
}
findBetweenDates(start: string, end: string): Promise<T> {
return new Promise(() => {})
}
create(item: Ticket): Promise<boolean> {
return new Promise(() => {})
}
update(id: string, item: Ticket): Promise<boolean> {
return new Promise(() => {})
}
delete(id: string): Promise<boolean> {
return new Promise(() => {})
}
}
Where is the Liskov principle in all of this? We separated the interfaces which gave us some pros and cons. We could implement in each repo some interfaces and no others at will. We could override differently each interface and keep the consistency of signatures. Also, we could escalate separately the write and read operations respectively. We could do all of that and “show will go on” the same. Our repository layer is a set of replaceable “black boxes” without rework and risks.
That’s the Liskov magic. But what about the cons? We might want to partially implement one of those interfaces. In fact, if that single interface grows the possibility of accessing the logic only as needed becomes more relevant.
There’s another issue that the implementation that we’re going to show you following resolves. Using interfaces for the repository abstraction would leave the door open to infinite instances. Even when these are risk it depends always on the business logic you’re working on to be considered right or wrong decision. If we assume that is wrong decision and then we have to choose using an abstract class.
// this class only can be extended
export abstract class BaseRepository<T> implements IWrite<T>, IRead<T> {
find(item: T): Promise<T[]> {
/* for explanation purposes we instatiate a Promise
your query should be here */
return new Promise(() => [])
}
findOne(id: string): Promise<T> {
return new Promise(() => {})
}
findBetweenDates(start: string, end: string): Promise<T> {
return new Promise(() => {})
}
create(item: T): Promise<boolean> {
return new Promise(() => {})
}
update(id: string, item: T): Promise<boolean> {
return new Promise(() => {})
}
delete(id: string): Promise<boolean> {
return new Promise(() => {})
}
}
Finally, we can declare a class as an extension of the BaseRepository class. That allows us to access by inheritance the features on the interfaces implemented by the parent class. This Base Repository class plays as an extension of behaviour in the way we used interfaces before. Thanks to this abstract class we can now partially implement the methods of the higher level of code as we needed and also add those which only make sense for a single repo. Like this:
class TicketRepository extends BaseRepository<Ticket> {
find(id: string): Promise<Ticket[]> {
return new Promise(() => {
/* her goes the real query
no need of this Promise instance */
})
}
fixTicket(id:string, ticketData: Ticket){
/* some specfic query that only this repo requires
besides the interface signatures */
}
}
The “I”: Interface segregation. Focus: ‘I’m the ball’
Doing one thing allows to do it better. Specialization should be considered simultaneously with segregation to comply our target of a SOLID fractal at every level. Our abstractions and every code we include to extend our modules should respect the principles as well. It makes no sense at all to split code and leave a mess in a superior level. But it’s not that easy to see when we are at the same level working with abstractions.
We could easily mix behaviour that should be split into different interfaces or extensions of behaviour at the same level despite we are correctly decoupling from our classes or entities because the reason to change clearly diverge in each case. That’s why we should focus and concentrate on group and segregate features in our abstractions by their main responsibilities as we said following the first principle.
Let’s make another assumption then: we want to include the parking behaviour as we made with storage at the “I” principle. We could feel tempted to include every behaviour related to the vehicle entity in one single interface. Something like this:
interface VehicleOperations<T> {
driveIn: (vehicleId: string) => {
/* signature of parking in method */
};
driveOut: (vehicleId: string) => {
/* signature of parking out method */
};
openTicket: (vehicleId: string) => {
/* signature for time tracking start method */
};
closeTicket: (vehicleId: string) => {
/* signature for time tracking stop method */
};
}
Posterior changes did it again. Even when we found a cool name for our interface some issues come up immediately. Remember we had a vehicle controller. If we follow up the same criteria will find out that in all our app we only have one controller, because in a parking lot business logic everything has to do with vehicles. If the criteria we’re following make us “break” our app every time that we must make it grow we have a clue we are mistaken, just like here.
It is hard to defend that every calculation about money income should be mixed up with other features. It is a feature that we cannot afford to handle without preventing errors, which justifies isolation. We should segregate it properly because the reason to change for money income calculation and the one for the vehicle data are different, we are talking about different “concerns”. (E.g.: tax rules often change in some countries, or pricing rules change due to market circumstances, etc).
This is what interface segregation is all about: coherently applying single responsibility criteria or singular concern to the abstractions we use to extend behaviour. Let’s make it happen for our example, also combined with what we said about MVC. This means including a ticket entity, a ticket controller with its ticket repository:
class Ticket {
constructor(
id: string,
vehicleId: string,
public _startTime: string,
public _endTime: string,
public _active: boolean
) { }
get startTime(): string {
return this._startTime;
}
get endTime(): string {
return this._endTime;
}
get active(): boolean {
return this._active;
}
}
It’s key to understand that we shouldn’t confuse the start time and end in town with its proper calculation of the total price. We avoid issues regarding how to relate the ticket to the vehicle as well as the unique ID generation for explanation purposes. All concerns of our ticket controller.
/* repository concrete implementation for ticket */
class TicketRepository<T extends Ticket> implements RepositoryInterface<T> {
add(ticket: Ticket): void {
// Save Ticket in the database
}
update(ticketId: string, ticket: Ticket): void {
// update Ticket in the database with new data;
;
}
}
We add a segregated abstractions layer for repositories and controllers for each entity: ticket and vehicle. This way changes on the entity vehicle won’t affect the entity ticket. We are accomplishing both principles of extension of behaviour without changes as well as a single concern per module.
The “D”: Dependency inversion. Scaping from domino effect
Let’s start considering the hierarchy of our modules. We have discussed how our modules should be so far. A well with about the relationship between models should be as well. In some of the previous analyses regarding the other principles. Nevertheless, we always consider the relationship between only two modules despite all knowing that our application should have a lot of them.
During runtime our modules depend on each other. Some processes depend on the results of previous ones. Previous principles could help us with that but it’s not enough. Even using interface segregation properly, we could find ourselves in an endless alley. We need a cross-strategy in our apps to relate modules efficiently when it comes to dependency between modules.
Let’s see an example of this problem. Remember we have our TicketController. But this time we’re going to add an abstraction layer. We’re going to introduce a service as an intermediate between the controller and the repository. But first we ned to update our Ticket entity:
class Ticket {
constructor(
id: string,
vehicleId: string,
private _startTime: string,
private _endTime: string,
private _active: boolean
) { }
get startTime(): string {
return this._startTime;
}
get endTime(): string {
return this._endTime;
}
get active(): boolean {
return this._active;
}
}
The proper update at TicketController
class TicketController {
/* the rest of logic for the proper
implementation of controller*/
openTicket = (vehicleId: string) => {
ticketService.create(vehicleId)
}
closeTicket = (ticketId: string, ticket: Ticket) => {
/* call to ticket service for update */
}
}
And now let’s pay some attention to the issues that this service could imply. For start we are using a third-party library to give our tickets a unique ID (uuid). However, even when we have it one single reason to change that allowed us properly segregating this ticket service we need to handle three different kinds of features in order to accomplish this single concern. We need to give this ticket a unique ID a timestamp and we have to call the repository to make a query in our DB and adding of this new ticket. Look at this first try:
class TicketService {
startTime = (): string => {
return new Date().toISOString().substring(0, 19);
}
create = (vehicleId: string): void => {
const id = uuidv4();
const startTime = this.startTime()
const newTicket: Ticket = new Ticket(id, vehicleId, startTime, '', true)
ticketRepository.add(newTicket)
}
}
This first try has some issues. We separated the features related to time tracking from our controller to our service. But if we must make some changes regarding the way we track time in our app as a cross-feature we are going to have to refactor this service. Besides the fact that our handler is now taking two concerns (time-tracking and ticket-issuing). And last but not least the fact that some posterior change in our ticket service could lead to involuntary errors in the way we track time we cannot afford to have.
The correct solution is to make the ticket service rely on the time tracking interface and not making depend on another class to make the timestamp. In practical terms this means to send the start time function or any other signature to be implemented to a higher level. Like this:
interface TimeTracking {
start(): string;
end(): void;
count(start: string, end: string): void;
}
Being coherent with the principles that we’ve been explaining so far we going to split our time tracker for tickets into a class. In particular, this handler is going to concretely implement the time-tracking behaviour for the ticket-related features. This allows us to add the special logic needed for this ticket feature. Independently from other flows where the timer tracking could be also required as behaviour. Like this:
class TimeTicketHandler implements TimeTracking {
start(): string {
return new Date().toISOString().substring(0, 19);
}
end(): void {
/* logic for ending */
}
count(start: string, end: string): void {
/* logic for counting */
}
}
And now our TicketService class will look like this:
class TicketService {
private th: TimeTicketHandler;
create = (vehicleId: string): void => {
const id = uuidv4();
const startTime = this.th.start()
/* you could call a builder method here */
const newTicket: Ticket = new Ticket(id, vehicleId, startTime, '', true)
ticketRepository.add(newTicket)
}
}
}
As you might see we work in this class with an instance of the time tracker from a higher level. We are accessing the handler’s features from an instance, separating concerns and extending behaviour without introducing modifications in the class.
Do not make modules depend on each other at the same level. Splitting functionalities using the criterion of single responsibility or single reason to change would be enough if both features could be completely isolated without malfunctioning or error. In terms of the parent-child relationship as we often say about components: children at the same level shouldn’t rely on each other. The correct technique is to send code to a higher level, once again. This means that both children should rely or depend on the same parent.
This is consistent with the logic tree structure that we talked about before. We’re doing nothing else than isolating or splitting behaviour that both modules depend on obtaining all the benefits that we explained: easier unit test coverage increasing, bug isolation, easier posterior refactor, and many others.
Conclusions
- SOLID principles are an amazing guide to develop but they’re not dogmas. Use them with practice logic.
- It’s unavoidable to make a trade-off between principles at the time of applying them.
- Write your code to be ready for easily refactor, escalation, or split responding to posterior changes.
- The business logic of the product as you’re working on is going to tell you whether is good to use some criterion or not. If life and ideas do not match then life should prevail.
- Always be creative and play around with the features that might allow you to make your project SOLID.
Thanks for reading!

About us Possumus
We are a company focused on creating value, driving businesses to achieve their digital transformation with strategy, knowledge, and innovation.
Our processes are accredited by ISO 9001:2015 certification in quality software development.
POSSUMUS, Microsoft Partner
Products

Copyright © 2026 Possumus. All Rigths Reserved.