SRE
Descubre el comportamiento de tu aplicación con observabilidad y pruebas de performance
01 October 2024 | Por Cristian Hernandez, Rodrigo Noya and Facundo Miglio
Conocer el comportamiento de una aplicación es una tarea desafiante, implica la utilización de diversas técnicas y tecnologías que nos ayuden a responder a interrogantes como saber si estamos listos para salir al mercado y qué tan bien preparados estamos para este.

Descubre el comportamiento de tu aplicación con observabilidad y pruebas de performance
En este artículo exploraremos algunas de las tecnologías que hemos aplicado a distintos clientes con el objetivo de brindarles claridad y tranquilidad a la hora de realizar sus negocios, podremos conocer por ejemplo si estamos listos para desplegar una solución en ambientes productivos y cuántos clientes podría atender la misma sin que se ocurra una interrupción en el servicio (Downtime). Por otro lado, también nos ayudarán a tener productos de mayor calidad, lograr una mejor experiencia de usuario, tener una alerta temprana de errores e incluso disminuir costos optimizando la infraestructura.
Ya seas desarrollador, encargado de calidad o cualquier rol del amplio mundo IT, este artículo te resultará muy útil e interesante ya que es transversal a diversas disciplinas y se trata, a fin de cuentas, de traer transparencia y seguridad a la hora de operar un negocio tecnológico tomando decisiones informadas.
El Desafío
Hace unos meses uno de nuestros clientes nos preguntó:
“Se acerca el HotSale... ¿Puede mi tienda soportar 10 veces la cantidad normal de clientes?”
Poder brindar una respuesta a esta pregunta aparentemente simple planteó un desafío significativo.
Debido a la naturaleza del negocio de nuestro cliente y su aplicación de e-commerce, debimos realizar una investigación y relevamiento exhaustivo para proporcionar una respuesta certera basada en datos, y de esta manera, poder garantizar que el negocio de nuestro cliente continuara operando eficientemente bajo grandes exigencias.
Comúnmente cuando se presentan este tipo de situaciones y un sistema no se comporta de la forma esperada, es frecuente el pensar que puede solucionarse simplemente “asignando más recursos” a la infraestructura, es decir, escalar verticalmente.
Vale mencionar que realizar un escalado vertical a ciegas representa un problema ya que mayores recursos no necesariamente implican mejores resultados y por otro lado tampoco sabríamos cuántos recursos dedicar, nos limitaríamos a un “prueba y error” mientras vamos ajustando el sistema sin mucha claridad y esperando lo mejor.
Desde una perspectiva empresarial, esto se traduce en gastar más sin la certeza de obtener mejores resultados.
Por ello, la capacidad de evaluar y predecir el comportamiento de nuestras aplicaciones es fundamental, especialmente cuando se anticipa una gran carga, como en el caso de nuestro cliente.
Aquí es donde entran en juego la “Observabilidad” y las “pruebas de performance”.
Entendemos por Observabilidad a la capacidad de comprender el estado de un sistema basándonos en los datos que éste genera, lo cual permite (entre otras ventajas):
- Visualizar su comportamiento en tiempo real
- Detectar problemas rápidamente
- Mejora la toma de decisiones ya que serán informadas.
Por otro lado, las pruebas de performance permiten comprobar cómo se comporta nuestro sistema bajo condiciones normales (average load test) y de estrés (stress tests), también pueden utilizarse para encontrar las capacidades máximas del sistema (breakpoint test) que en nuestro caso respondería a la pregunta: “¿a cuántos clientes puede atender nuestro e-commerce?”
¿Cómo aplicamos estas prácticas con nuestro cliente?
Investigación e implementación
-
Observabilidad: utilizamos para esto el stack de Grafana con Prometheus y valiéndonos de múltiples“exporters” por cada servicio que queremos supervisar, por ejemplo, métricas del sistema, bases de datos, entre otros.
-
Pruebas de performance: elegimos entre varias opciones a K6 dado que cumplía con nuestras necesidades. K6 es ampliamente utilizada y mantenida por Grafana. Un aspecto importante es que podemos analizar la salida de las pruebas usando dashboards de esta última herramienta pudiendo aprovechar la implementación realizada para el monitoreo.
Los elementos mencionados se instalaron en una Instancia dedicada. Sin embargo, esta misma solución se puede implementar de diversas formas, por ejemplo, utilizando un clúster de Kubernetes (K8S). Esta última fue la opción elegida para ejecutar las pruebas de carga, ya que se requería una gran cantidad de recursos y correr tests en simultaneo, características que el clúster del cliente brindaba.
Realizando las pruebas de performance
Usando K6 podemos plantear las pruebas de diversas formas, en nuestro caso elegimos escribirlas como código JavaScript que luego era enviado al cluster para ser ejecutado con la configuración respectiva.
Las salidas fueron analizadas con nuestra implementación de Grafana utilizando sus dashboards.
A continuación, podemos ver la salida de las pruebas en la versión Cloud que se usaron para poner a punto la solución en el cluster:
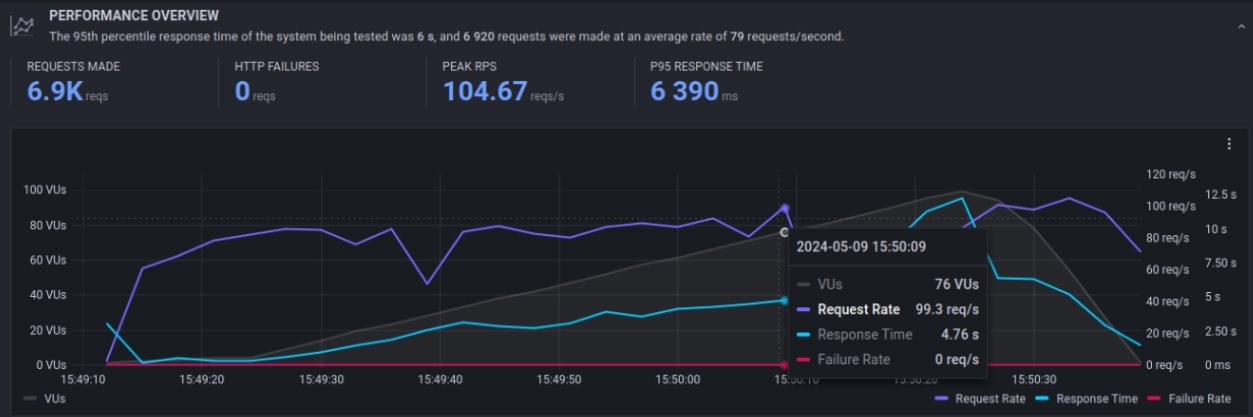
Dentro de los datos observables tendremos por ejemplo la cantidad de request (solicitudes) por segundo que estamos haciendo al e-commerce, el tiempo de respuesta y otros datos relevantes que nos permiten, junto al monitoreo, tener indicios de cómo se comporta la aplicación y poder tomar decisiones informadas.
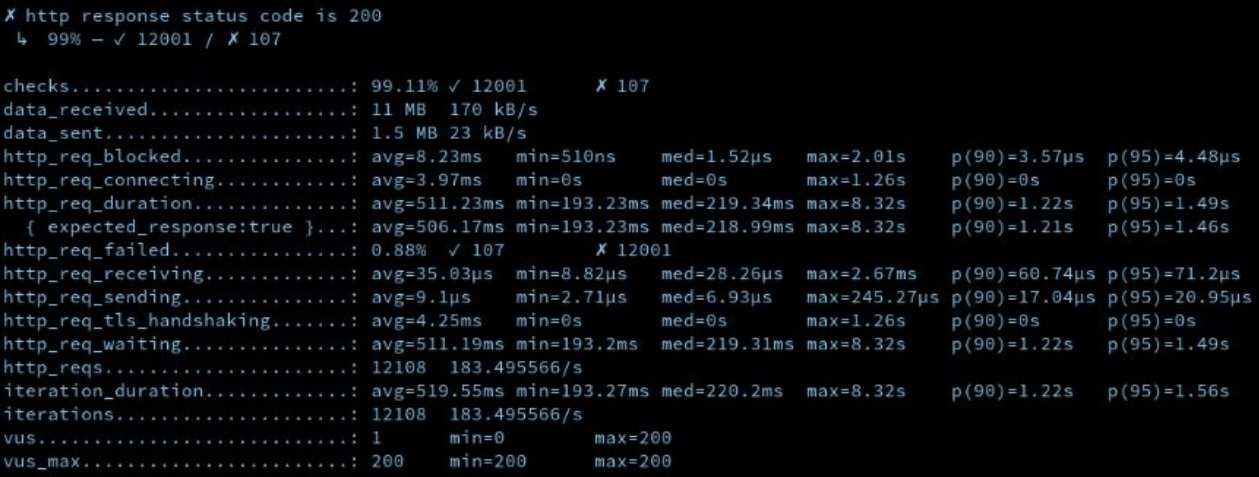
También podemos ver los mismos datos sin graficar en la salida de “consola” de K6 que para pruebas de menor complejidad nos puede resultar útil:
Para entender las capacidades del sistema y cómo cambiar los recursos afecta al mismo, debemos generar escenarios que lo exijan de diferentes formas, mientras estas pruebas se ejecutan tendremos que analizar nuestro monitoreo para verificar cómo las solicitudes de los clientes afectan los recursos del sistema.
En nuestro caso utilizamos pruebas de carga normales (average) para comprender el funcionamiento típico del mismo, luego propusimos pruebas mucho más exigentes (stress y breakpoint) para encontrar la cantidad máxima de clientes que podrían ser atendidos en un uso normal de la tienda.
Con estas pruebas establecidas, modificamos los recursos del entorno de desarrollo de la tienda y las ejecutamos nuevamente para observar los cambios en la cantidad de clientes que se podrían atender. Inicialmente no se observó un gran aumento, con lo pudimos validar la hipótesis de que “Mayor cantidad de recursos no implica necesariamente un mayor rendimiento.”
Como Insight pudimos detectar, tras una pequeña investigación, que era necesario reconfigurar elementos internos del e-commerce para que pudieran aprovecharse los nuevos recursos, atendiendo finalmente a más compradores.
Proactividad en la solución de errores
Contar con un sistema de monitoreo, incluso con alarmas, no es suficiente ya que este modelo es reactivo. Es decir que “Actuamos cuando vemos algo roto o a punto de romperse”.
Por otro lado, incorporar pruebas de performance sobre todo si son automáticas nos permite tener un enfoque proactivo donde “Podemos detectar problemas antes de que lleguen a producción y por ende a los clientes”. De esta forma conoceremos las capacidades y limitaciones de nuestro producto.
Estas actividades son complementarias y no excluyentes, ambas son necesarias para desarrollar servicios de mayor calidad y reducir la posibilidad de una caída de servicio afectando al negocio.
Conclusión
Cómo impactó en el cliente la observabilidad y pruebas de performance
- Experiencia de usuario: Mejoró la experiencia del usuario conociendo cómo se comportan los sistemas y viendo dónde es necesario ajustar.
- Prevención: Se pudo determinar las limitaciones del sistema antes de que sea tarde.
- Mejorar la calidad del producto: Se puedo estándares mínimos de calidad que el producto debe cumplir antes de llegar a entornos productivos
- Optimizar infraestructura: Fue posible ajustar los costos en infraestructura al conocer qué necesita el sistema realmente para lograr una buena experiencia de usuario.
Tener conocimiento del comportamiento de nuestros sistemas es necesario y una ventaja con la que debemos contar, podremos ofrecer un mejor servicio y tener mayor tranquilidad al hacerlo, reduciendo las posibilidades de que se presenten errores que afecten a los clientes y por ende al negocio.
About us Possumus
Somos una compañía enfocada en crear valor, que impulsa a las empresas a lograr su transformación digital con estrategia, conocimiento e innovación.
Nuestros procesos están acreditados con la certificación ISO 9001:2015 de calidad en desarrollo de software.
POSSUMUS, Partner de Microsoft
Products

Copyright © 2026 Possumus. All Rigths Reserved.